關于數據分析,你需要知道的ETL基礎知識
時間:2021-07-16來源:億信ABI知識庫瀏覽數:152次
信息是現代企業的重要資源,是企業運用科學管理、決策分析的基礎。據統計,數據量每經過2-3年時間就會成倍增長,這些數據蘊含著巨大的商業價值,而企業所關注的通常只占總數據量的2%~4%左右。因此,企業仍然沒有最大化地利用已存在的數據資源,以至于浪費了更多的時間和資金,也失去制定關鍵商業決策的最佳契機。
于是,企業如何通過各種技術手段,并把數據轉換為信息、知識,已經成了提高其核心競爭力的關鍵,其中的數據處理在大數據的生態中始終處于不可缺少的地位,因為數據處理的時效性,準確性直接影響數據的分析與挖掘,分析的最終結果影響業務的營銷與收入。
今天我們就來說說一種重要的數據分析處理手段ETL(Extract-Transform-Load)。
 舉個例子,某電商公司分析人員根據訂單數據進行用戶特征分析。這時需要基于訂單數據,計算一些相應的分析指標,如每個用戶的消費頻次,銷售額最大的單品,用戶復購時間間隔等,這些指標都要通過計算轉換得到。
舉個例子,某電商公司分析人員根據訂單數據進行用戶特征分析。這時需要基于訂單數據,計算一些相應的分析指標,如每個用戶的消費頻次,銷售額最大的單品,用戶復購時間間隔等,這些指標都要通過計算轉換得到。
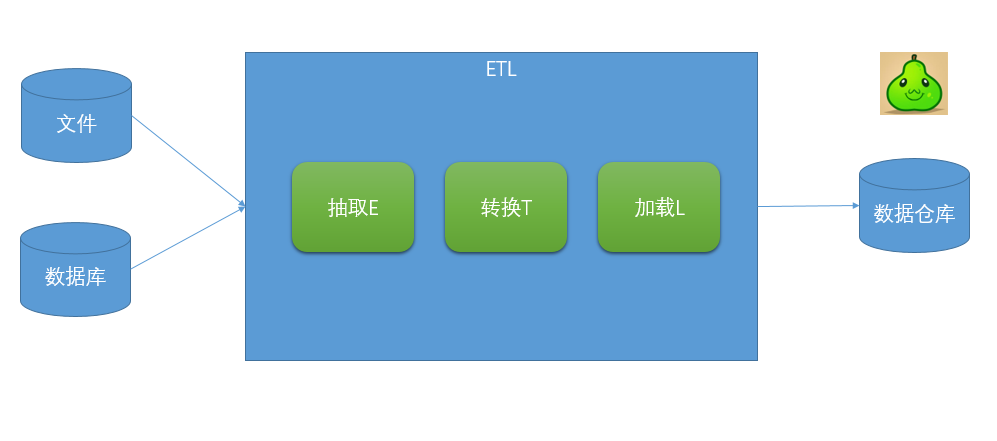
 ETL架構按其字面含義理解就是按照E-T-L這個順序流程進行處理的架構:先抽取、然后轉換、完成后加載到目標數據庫中。
在ETL架構中,數據的流向是從源數據流到ETL工具,ETL工具是一個單獨的數據處理引擎,一般會在單獨的硬件服務器上,實現所有數據轉化的工作,然后將數據加載到目標數據倉庫中。如果要增加整個ETL過程的效率,則只能增強ETL工具服務器的配置,優化系統處理流程(一般可調的東西非常少)。
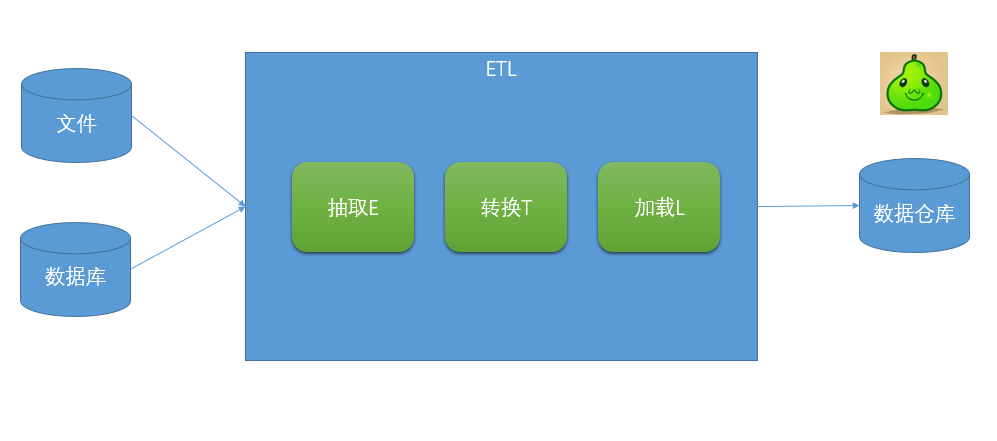
ETL架構按其字面含義理解就是按照E-T-L這個順序流程進行處理的架構:先抽取、然后轉換、完成后加載到目標數據庫中。
在ETL架構中,數據的流向是從源數據流到ETL工具,ETL工具是一個單獨的數據處理引擎,一般會在單獨的硬件服務器上,實現所有數據轉化的工作,然后將數據加載到目標數據倉庫中。如果要增加整個ETL過程的效率,則只能增強ETL工具服務器的配置,優化系統處理流程(一般可調的東西非常少)。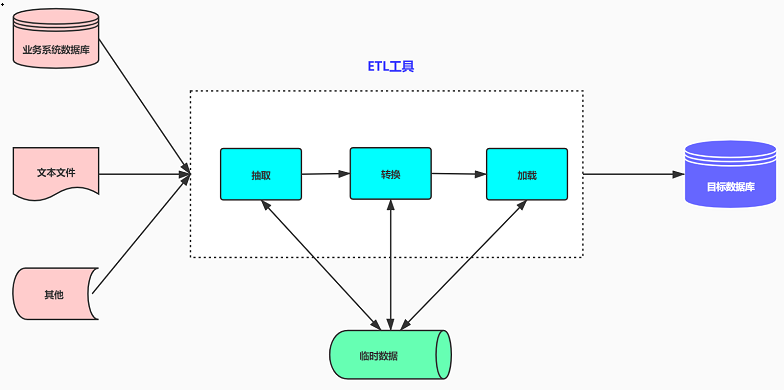 ELT架構則把“L”這一步工作提前到“T”之前來完成:先抽取、然后加載到目標數據庫中、在目標數據庫中完成轉換操作。在ELT架構中,ELT只負責提供圖形化的界面來設計業務規則,數據的整個加工過程都在目標和源的數據庫之間流動,ELT協調相關的數據庫系統來執行相關的應用,數據加工過程既可以在源數據庫端執行,也可以在目標數據倉庫端執行(主要取決于系統的架構設計和數據屬性)。當ETL過程需要提高效率,則可以通過對相關數據庫進行調優,或者改變執行加工的服務器就可以達到。
ELT架構的特殊優勢:①ELT主要通過數據庫引擎來實現系統的可擴展性;②ELT可以保持所有的數據始終在數據庫當中,避免數據的加載和導出,從而保證效率,提高系統的可監控性;③ELT可以根據數據的分布情況進行并行處理優化,并可以利用數據庫的固有功能優化磁盤I/O;④ELT的可擴展性取決于數據庫引擎和其硬件服務器的可擴展性;⑤通過對相關數據庫進行性能調優,ELT過程獲得3到4倍的效率提升一般不是特別困難。
(1)當您想要執行復雜的計算時,ETL工具比數據倉庫或數據池更有效(2)如果要在加載到目標存儲之前進行大量數據清理。ETL是一種更好的解決方案,因為您不會將不需要的數據移動到目標。(3)當您僅使用結構化數據或傳統結構化數據倉庫時。ETL工具通常最有效地將結構化數據從一個環境移動到另一個環境。(4)當你想要擴展補充數據時。如果要在將數據移動到目標存儲時擴展補充數據,則需要使用ETL工具。例如,添加時間戳。
ELT架構則把“L”這一步工作提前到“T”之前來完成:先抽取、然后加載到目標數據庫中、在目標數據庫中完成轉換操作。在ELT架構中,ELT只負責提供圖形化的界面來設計業務規則,數據的整個加工過程都在目標和源的數據庫之間流動,ELT協調相關的數據庫系統來執行相關的應用,數據加工過程既可以在源數據庫端執行,也可以在目標數據倉庫端執行(主要取決于系統的架構設計和數據屬性)。當ETL過程需要提高效率,則可以通過對相關數據庫進行調優,或者改變執行加工的服務器就可以達到。
ELT架構的特殊優勢:①ELT主要通過數據庫引擎來實現系統的可擴展性;②ELT可以保持所有的數據始終在數據庫當中,避免數據的加載和導出,從而保證效率,提高系統的可監控性;③ELT可以根據數據的分布情況進行并行處理優化,并可以利用數據庫的固有功能優化磁盤I/O;④ELT的可擴展性取決于數據庫引擎和其硬件服務器的可擴展性;⑤通過對相關數據庫進行性能調優,ELT過程獲得3到4倍的效率提升一般不是特別困難。
(1)當您想要執行復雜的計算時,ETL工具比數據倉庫或數據池更有效(2)如果要在加載到目標存儲之前進行大量數據清理。ETL是一種更好的解決方案,因為您不會將不需要的數據移動到目標。(3)當您僅使用結構化數據或傳統結構化數據倉庫時。ETL工具通常最有效地將結構化數據從一個環境移動到另一個環境。(4)當你想要擴展補充數據時。如果要在將數據移動到目標存儲時擴展補充數據,則需要使用ETL工具。例如,添加時間戳。
— 01 —ETL發展的歷史背景
隨著企業的發展,各業務線、產品線、部門都會承建各種信息化系統方便開展自己的業務。隨著信息化建設的不斷深入,由于業務系統之間各自為政、相互獨立造成的數據孤島”現象尤為普遍,業務不集成、流程不互通、數據不共享。這給企業進行數據的分析利用、報表開發、分析挖掘等帶來了巨大困難。 在此情況下,為了實現企業全局數據的系統化運作管理(信息孤島、數據統計、數據分析、數據挖掘) ,為DSS(決策支持系統)、BI(商務智能)、經營分析系統等深度開發應用奠定基礎,挖掘數據價值 ,企業會開始著手建立數據倉庫,數據中臺。將相互分離的業務系統的數據源整合在一起,建立一個統一的數據采集、處理、存儲、分發、共享中心,從而使公司的成員能夠從不同業務部門查看綜合數據,而這個過程中使用的數據處理方法之一就是ETL。 ETL是數據中心建設、BI分析項目中不可或缺的環節。各個業務系統中分布的、異構的數據源,經過ETL過程的數據抽取、轉換,最終存儲到目標數據庫或者數據倉庫,為上層BI數據分析,或其他業務功能做數據支撐。
— 02 —什么是ETL?
ETL,Extract-Transform-Load的縮寫,是將業務系統的數據經過抽取、清洗轉換之后加載到數據倉庫的過程。ETL是數據集成的第一步,也是構建數據倉庫最重要的步驟,目的是將企業中的分散、零亂、標準不統一的數據整合到一起,為企業的決策提供分析依據。ETL一詞較常用在數據倉庫,但其對象并不限于數據倉庫。
舉個例子,某電商公司分析人員根據訂單數據進行用戶特征分析。這時需要基于訂單數據,計算一些相應的分析指標,如每個用戶的消費頻次,銷售額最大的單品,用戶復購時間間隔等,這些指標都要通過計算轉換得到。
— 03 —ETL的流程
ETL如同它代表的三個英文單詞,涉及三個獨立的過程:抽取、轉換和加載。工作流程往往作為一個正在進行的過程來實現,各模塊可靈活進行組合,形成ETL處理流程。 1.數據抽取 數據抽取指的是從不同的網絡、不同的操作平臺、不同的數據庫和數據格式、不同的應用中抽取數據的過程。目標源可能包括ERP、CRM和其他企業系統,以及來自第三方源的數據。 不同的系統傾向于使用不同的數據格式,在這個過程中,首先需要結合業務需求確定抽取的字段,形成一張公共需求表頭,并且數據庫字段也應與這些需求字段形成一一映射關系。這樣通過數據抽取所得到的數據都具有統一、規整的字段內容,為后續的數據轉換和加載提供基礎,具體步驟如下: ①確定數據源,需要確定從哪些源系統進行數據抽取②定義數據接口,對每個源文件及系統的每個字段進行詳細說明③確定數據抽取的方法:是主動抽取還是由源系統推送?是增量抽取還是全量抽取?是按照每日抽取還是按照每月抽取? 2.數據轉換 數據轉換實際上還包含了數據清洗的工作,需要根據業務規則對異常數據進行清洗,主要將不完整數據、錯誤數據、重復數據進行處理,保證后續分析結果的準確性。 數據轉換就是處理抽取上來的數據中存在的不一致的過程。數據轉換一般包括兩類:第一類:數據名稱及格式的統一,即數據粒度轉換、商務規則計算以及統一的命名、數據格式、計量單位等;第二類:數據倉庫中存在源數據庫中可能不存在的數據,因此需要進行字段的組合、分割或計算。主要涉及以下幾個方面: ①空值處理:可捕獲字段空值,進行加載或替換為其他含義數據,或數據分流問題庫②數據標準:統一元數據、統一標準字段、統一字段類型定義③數據拆分:依據業務需求做數據拆分,如身份證號,拆分區劃、出生日期、性別等④數據驗證:時間規則、業務規則、自定義規則⑤數據替換:對于因業務因素,可實現無效數據、缺失數據的替換⑥數據關聯:關聯其他數據或數學,保障數據完整性 3.數據加載 數據加載的主要任務是將經過清洗后的干凈的數據集按照物理數據模型定義的表結構裝入目標數據倉庫的數據表中,如果是全量方式則采用LOAD方式,如果是增量則根據業務規則MERGE進數據庫,并允許人工干預,以及提供強大的錯誤報告、系統日志、數據備份與恢復功能。整個操作過程往往要跨網絡、跨操作平臺。 在實際的工作中,數據加載需要結合使用的數據庫系統(Oracle、Mysql、Spark、Impala等),確定最優的數據加載方案,節約CPU、硬盤IO和網絡傳輸資源。
— 04 —ETL與ELT有什么區別?
ETL架構按其字面含義理解就是按照E-T-L這個順序流程進行處理的架構:先抽取、然后轉換、完成后加載到目標數據庫中。
在ETL架構中,數據的流向是從源數據流到ETL工具,ETL工具是一個單獨的數據處理引擎,一般會在單獨的硬件服務器上,實現所有數據轉化的工作,然后將數據加載到目標數據倉庫中。如果要增加整個ETL過程的效率,則只能增強ETL工具服務器的配置,優化系統處理流程(一般可調的東西非常少)。
ELT架構則把“L”這一步工作提前到“T”之前來完成:先抽取、然后加載到目標數據庫中、在目標數據庫中完成轉換操作。在ELT架構中,ELT只負責提供圖形化的界面來設計業務規則,數據的整個加工過程都在目標和源的數據庫之間流動,ELT協調相關的數據庫系統來執行相關的應用,數據加工過程既可以在源數據庫端執行,也可以在目標數據倉庫端執行(主要取決于系統的架構設計和數據屬性)。當ETL過程需要提高效率,則可以通過對相關數據庫進行調優,或者改變執行加工的服務器就可以達到。
ELT架構的特殊優勢:①ELT主要通過數據庫引擎來實現系統的可擴展性;②ELT可以保持所有的數據始終在數據庫當中,避免數據的加載和導出,從而保證效率,提高系統的可監控性;③ELT可以根據數據的分布情況進行并行處理優化,并可以利用數據庫的固有功能優化磁盤I/O;④ELT的可擴展性取決于數據庫引擎和其硬件服務器的可擴展性;⑤通過對相關數據庫進行性能調優,ELT過程獲得3到4倍的效率提升一般不是特別困難。
(1)當您想要執行復雜的計算時,ETL工具比數據倉庫或數據池更有效(2)如果要在加載到目標存儲之前進行大量數據清理。ETL是一種更好的解決方案,因為您不會將不需要的數據移動到目標。(3)當您僅使用結構化數據或傳統結構化數據倉庫時。ETL工具通常最有效地將結構化數據從一個環境移動到另一個環境。(4)當你想要擴展補充數據時。如果要在將數據移動到目標存儲時擴展補充數據,則需要使用ETL工具。例如,添加時間戳。
關于億信華辰
億信華辰是中國專業的智能數據產品與服務提供商,一直致力于為政企用戶提供從數據采集、存儲、治理、分析到智能應用的智能數據全生命周期管理方案,幫助企業實現數據驅動、數據智能,已積累了8000多家用戶的服務和客戶成功經驗,為客戶提供數據分析平臺、數據治理系統搭建等專業的產品咨詢、實施和技術支持服務。
(部分內容來源網絡,如有侵權請聯系刪除)
立即免費申請產品試用
免費試用
相關文章推薦
-

用數據分析助力企業決策與業務創新
發布時間:2023-09-26瀏覽量:79次
在數字化時代,數據分析已經成為企業成功的關鍵因素之一。作為國內領先的數據分析廠商,億信華辰一直致力于為各類企業提供最優質的數據分析產品和...查看詳情 -

為什么要學習數據分析?數據分析產出是什么?
發布時間:2022-06-28瀏覽量:970次
「過去」以往在增量時代,每天都有新的領域、新的市場被開發。尤其是在互聯網、電商等領域的紅利期,似乎只要做好單點的突破就能獲得市場。這個蠻...查看詳情 -

數據分析很痛苦?5個對策、8大方法幫到你!
發布時間:2022-06-15瀏覽量:263次
“對數據敏感,能夠通過數據分析與反饋,不斷改進和優化產品”之類的招聘要求屢見不鮮。誠然,數據分析能力已經成為產品經理不可或缺的技能。數據...查看詳情 -

淺談大數據的過去、現在和未來
發布時間:2022-06-14瀏覽量:544次
相信身處于大數據領域的讀者多少都能感受到,大數據技術的應用場景正在發生影響深遠的變化: 隨著實時計算、Kubernetes 的崛起和 HTAP、流批一體...查看詳情 -

數字經濟時代,企業的核心競爭力究竟是什么?
發布時間:2022-06-14瀏覽量:755次
數字經濟時代對于企業而言意味著全新的挑戰和機遇,如何抓住數字經濟的本質,而不是停留在各種零碎的、華麗的詞藻堆砌,構建企業核心競爭力新的理...查看詳情
相關主題

